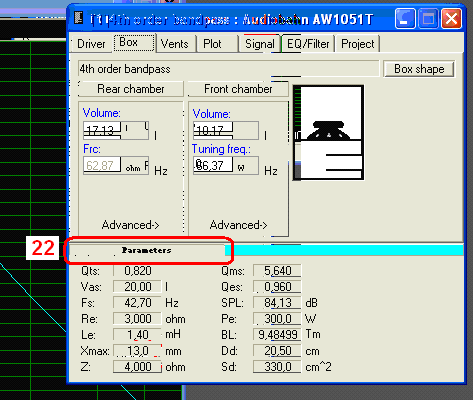
Programma Dlya Rascheta Korpusa Sabvufera Na Russkom Yazike
Wrote: 21 May 2015, 08:05 PM Your patience is very much appreciated!  In the mean time if you want to continue discussing it via PM, I'll be happy to keep you updated on the situation.
In the mean time if you want to continue discussing it via PM, I'll be happy to keep you updated on the situation.
1 CREATE TABLE COUNTER ( 2 type text, 3 actor text, 4 version bigint, 5 increment int, 6 PRIMARY KEY(type, actor, version)) Let’s say we have to keep count of how many shares of IBM are currently being traded in the market. CVRDT: 1 CREATE TABLE COUNTER ( 2 type text, 3 actor text, 4 version int, 5 increment int, 6 PRIMARY KEY(type, actor, version)) The above events will be captured as follows: 1 INSERT INTO COUNTER(type, actor, version, increment) VALUES('IBM', 'P1', 1, 1000); 2 INSERT INTO COUNTER(type, actor, version, increment) VALUES('IBM', 'P2', 1, 500); 3 INSERT INTO COUNTER(type, actor, version, increment) VALUES('IBM', 'P1', 2, 1500); Notice the difference in the last INSERT statement. Since this is a state-based CvRDT, the merge function will take the most recent value for each actor and calculate the sum of all the increments. 1 SELECT increment, version FROM COUNTER WHERE type = 'IBM' In this case, it will be 1500(for P1) + 500(for P2) = 2000. We can further optimize this using Cassandra’s last-write-wins policy if we use version as timestamp. The new table model will be: 1 CREATE TABLE COUNTER ( 2 type text, 3 actor text, 4 increment int, 5 PRIMARY KEY(type, actor)) And the new insert statements updated as: 1 INSERT INTO COUNTER(type, actor, increment) VALUES('IBM', 'P1', 1000) USING TIMESTAMP 1; 2 INSERT INTO COUNTER(type, actor, increment) VALUES('IBM', 'P2', 500) USING TIMESTAMP 1; 3 UPDATE COUNTER SET increment = 1500 WHERE type = 'IBM' AND actor = 'P1' USING TIMESTAMP 2; As noted above, the merge function for a CvRDT will take the most recent value for each actor and calculate the sum of all the increments.
As noted above, the merge function for a CvRDT will take the most recent value for each actor and calculate the sum of all the increments. 1 SELECT increment FROM COUNTER WHERE type = 'IBM' In this case, we just used Cassandra’s LWW policy to manage the most recent value for the actor. Pros: • Highly scalable since no coordination is required • No contention on inserts or updates • Associative and Commutative • Idempotent Cons: • Reads need to read all the records and take a sum • The row could get very wide which could slow down retrieval Garbage Collection As you can see with a CRDT, the rows could become very wide. Although Cassandra supports very wide rows, retrieval times could worsen as the number of events increase. The common way to address this in a CRDT is to have a garbage collector running in the background to periodically compact the row. Diktanti po belorusskomu yaziku dlya 4 klassa. Cassandra requires the clocks to be in sync. The usual way to achieve this is using or Network Time Protocol.

May 14, 2018 - (Translator Profile - Nick Golensky) Translation services in English to Russian (Advertising / Public Relations and other fields.). Skachat-videoredaktor-bez-klyucha-na-russkom.tekopia has the lowest Google pagerank and bad results in terms of Yandex topical citation index. We found that Skachat-videoredaktor-bez-klyucha-na-russkom.tekopia.ru is poorly ‘socialized’ in respect to any social network.